
56 billion parameters Mixtral 8X7b, consisting of a mini-model team, is outstanding. For instance, Lama 2 70b is just slightly smaller than this. However, what makes it unique from other similar models is its 32k-context window, enabling it to process long text patterns with a high degree of precision.
The mixture of experts model
The model has a hybrid ‘experts’ methodology. In the model, there are eight specialists who have their own strengths. It can be used for any task such as speech analysis, coding, and content development.
The Structure of Mixtral 8X7b
Mixtral 8X7b is a model of a transformer based on the Transformer architecture, which decomposes tasks into manageable pieces that suit different mini models. Such specialists are concerned with such matters as syntax, semantics, and style.
The Gating Function: Orchestrating the Experts
Acting as the decision-maker, the gating function determines who’s an expert for what job. It is trained incrementally, improving the performance of the model.
Innovative Features of Mixtral 8X7b
- The focus mechanism of the model is made simple through a process called grouped query attention.
- The sliding window is useful for handling large text segments.
- The bite fallback bpe tokenizer helps in increasing understanding of different inputs.
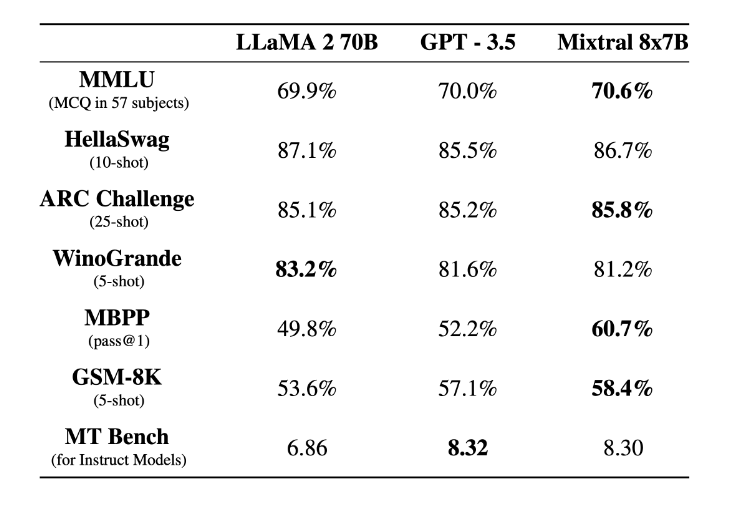
Benchmarking Against Other Models
In terms of perplexity, accuracy, BLU, and F1 scores, Mixtral 8X7b surpasses competitors like Meta Lama 2 and GPT 3.5. These scores reflect its superior language prediction, translation, and task completion capabilities.
 The Many Facets of Mixtral 8X7b’s Applications
The Many Facets of Mixtral 8X7b’s Applications
- Natural Language Processing: From summarizing articles to sentiment analysis.
- Coding Assistance: Aiding in code writing, debugging, and optimization.
- Content Generation: Capable of creating diverse and original content.
Harnessing the Power of Mixtral 8X7b for Diverse Projects
Delving into the intricate world of Mixtral 8X7b, one discovers a realm where complexity dances with versatility. This AI model’s fine-tuning process emerges not just as a mere step but as a journey, adaptable and malleable, catering to an array of data types. Imagine a chameleon constantly shifting and adapting—that’s Mixtral 8X7b in the realm of data. Its deployment? A flexible endeavour, stretching across the vast cloud services or nestling within the more intimate confines of edge devices. The choice hinges on a delicate balance of specific needs and available resources.
Navigating the Maze of Challenges
Venture deeper, and you’ll encounter a labyrinth of challenges. First, memory requirements. It’s like a game of tetris, balancing needs and capabilities. Strategies? Consider a smaller context window, akin to looking through a narrower lens but with sharper focus.
Consistency is key, and achieving it demands a tactical approach. Imagine a conductor leading an orchestra of experts; each must play in harmony. Fixed expert sets or verification mechanisms are the baton in this symphony, ensuring each note resonates with precision and coherence.
Concluding Thoughts on Mixtral 8X7b
Its versatility and adaptability are like water, taking the shape of whatever container it’s poured into. Yet, the journey with Mixtral 8X7b is not without its trials and tribulations. The right approach, a blend of creativity and pragmatism, can unlock realms of possibilities, turning challenges into stepping stones towards harnessing their full potential.



